Overview
For the final project in my ENGR 418 Machine Learning course, I built a Python-based computer vision system to identify and sort Lego bricks on a moving conveyor belt. The project simulates an industrial automation challenge. An optical sensor captures images of items moving along a conveyor belt, categorizes them using a machine learning algorithm, and routes them to their correct destinations based on their classification.
The core focus of this project was the development and optimization of the classification pipeline. Working with RGB images, the system was trained to identify and sort four distinct Lego shapes from a top-down view: 2x4 rectangles, 2x2 squares, 2x2 circles, and 2x1 rectangles.
The project was split into two distinct phases, moving from a basic raw-pixel model to a more robust, feature-engineered solution.
Core Technologies
This project was done entirely using the Python programming language.
The Libraries used for this project were:
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, accuracy_score
from PIL import Image
from PIL import ImageFilter
from PIL import ImageEnhanceComputer vision libraries like OpenCV were prohibited for this project.
Skills Demonstrated
- Image Processing: Grayscale conversion, resizing, and cropping using Python.
- Feature Engineering: Extracting spatial and geometric properties from images to handle rotation and misalignment.
- Model Optimization: Designing efficient ML models under strict hardware and parameter constraints.
- Validation: Evaluating performance using confusion matrices and accuracy scores on separate training and testing sets.
Stage 1 - Raw Image Classification
In this stage, I built a 4-class classifier using raw image data. This phase used an idealized dataset where all the Lego bricks were perfectly centered and oriented in the same direction.
- Preprocessing: Raw RGB images were converted to grayscale, scaled, and cropped into a uniform $64\times64$ pixel input.
- Constraints: To keep the model lightweight, the architecture was restricted to fewer than 4,097 trainable parameters (weights) per class.
Image Processing
Because the model had to rely entirely on raw pixel values rather than engineered geometric features, image preprocessing was critical to standardize the inputs.
The original RGB images were converted to grayscale to reduce unnecessary color channels and minimize computational complexity. Images were scaled and cropped into a uniform $64 \times 64$ pixel resolution. The final $64 \times 64$ grayscale images were flattened into a 4,096-dimensional input vector ($64 \times 64 = 4,096$), matching the parameter limit per class.
Model Architecture and Implementation
I implemented a 4-class Logistic Regression model using a One-vs-Rest (OvR) approach. By flattening the images to 4,096 pixels, the model utilized exactly 4,096 weights plus 1 bias parameter per class, optimizing the architecture right up to the allowable threshold.
The code was structured cleanly in a Python notebook with modular cells separating the workflows:
Data Ingestion: Built a robust function to dynamically read all files within the training and testing directories without assuming a fixed dataset size.
Training and Evaluation: The model was trained exclusively on the training folder dataset. Its performance was evaluated using a confusion matrix and overall accuracy to track classification errors across the four shapes.
Testing Function: I packaged the final trained model into a standalone, callable function,
test_function, allowing external test paths to be passed seamlessly for grading and validation.
Plotting the weights as images, the "memory" of each class can be seen after the model has learned. The figure below shows the weights for 2x4 rectangles, 2x2 squares, 2x2 circles, and 2x1 rectangles in order from left to right.
Model Accuracy
The model achieved exceptional classification performance across both datasets, capturing the raw pixel boundaries with high precision. It reached a perfect 100% accuracy on the training data, while maintaining a robust 98.6% accuracy when evaluated on the unseen test images.
Because Stage 1 used an idealized dataset where all pieces were perfectly centered and uniformly aligned, the model easily mapped the raw pixel boundaries of each shape. To gain further insight into the innaccuracies, a confusion matrix was generated.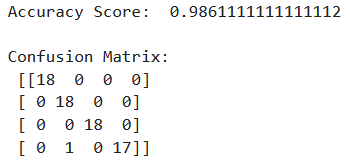
Breaking down what this matrix means:
- Row 1 (Actual 2x1 Rectangles): 18 images were tested, and all 18 were correctly predicted as 2x1 rectangles.
- Row 2 (Actual 2x2 Circles): 18 images were tested, and all 18 were correctly predicted as circles.
- Row 3 (Actual 2x4 Rectangles): 18 images were tested, and all 18 were correctly predicted as 2x4 rectangles.
- Row 4 (Actual 2x2 Squares): 18 images were tested. 17 were correctly predicted as squares, but 1 square image was incorrectly predicted as a circle (falling under Column 2, which corresponds to the 2x2 circles).
This means there is an occasional misclassifications occurring between the 2x2 square and 2x2 circle. Because they share the same stud count and general aspec ratio, the model sometimes confuses the two lego pieces.
A lightweight Logistic Regression model using exactly 4,096 weights per class is highly effective for industrial sorting under strict, controlled environmental conditions. However, this total reliance on raw pixel locations meant the model lacked spatial flexibility, making it vulnerable to the rotation and displacement introduced in Stage 2.
Stage 2 - Handling Real-World Variance
When tested against a more realistic dataset containing uncentered and randomly rotated Lego bricks, the baseline Stage 1 model failed. The objective for Stage 2 was to overhaul the processing pipeline to make the classifier translation and rotation invariant.
Hardware constraints were tightened further to simulate edge computing limits. Instead of 4,096 weights, the model was strictly limited to a maximum of 40 engineered features per image.
Instead of feeding raw pixels into the model, I extracted the geometric features of each image to make the system rotation and translation invariant.
Using 7 engineered features to train a 4-class logistic regression classifier, I generated a model that could accurately sort the displaced and rotated bricks with minimal processing overhead.
Image Processing
To extract clean geometric data regardless of a brick's position or rotation, I built a robust computer vision pipeline using Python's Pillow library. The raw images were passed through the following sequential filters:
Contrast and Normalization: Enhanced contrast by a factor of 1.35 and stretched the pixel values to occupy the full 0 to 255 grayscale range.
Noise Reduction: Applied a sharpness enhancer factor of 1.75 followed by a Gaussian Blur to smooth out visual artifacts.
Edge Detection and Cropping: Passed the image through a FIND_EDGES filter. To prevent the physical edges of the image boundary from being detected, an absolute padding of 28 pixels was cropped from the perimeter before resizing the image to 64x64 pixels.
Hysteresis Thresholding: Converted the image to pure monochrome using a dual-threshold system to isolate the distinct boundary of the Lego brick.
The figure below shows an example of the image processing on a 2x4 rectangle brick.
Feature Engineering
To measure features from the processed images, I wrote an algorithm to explicitly measure the geometric properties of the shapes.
The system programmatically rotated the processed edge-detected image through 16 angles (22.5 degree increments). At each angle, the algorithm calculated the bounding box width and height by summing the non-zero pixels across the horizontal and vertical axes. From this rotational sweep, I distilled the data down to just 7 engineered features:
- Maximum relative height across all rotations.
- Minimum relative height across all rotations.
- Maximum relative width across all rotations.
- Minimum relative width across all rotations.
- Maximum absolute difference between width and height.
- Aspect ratio based on minimum width and maximum height.
- Aspect ratio based on maximum width and minimum height.
Model Architecture
By feeding only these 7 engineered features into an optimized Logistic Regression model (tuned with C=18), the system achieved outstanding performance and completely overcame the spatial variance issues.
To evaluate how the model was making its decisions, I visualized the logistic regression weights using a heatmap.
Y-Axis (Target Classes):
0.2x1 Rectangles,1.2x2 Circles,2.2x4 Rectangles, and3.2x2 Squares.X-Axis (Engineered Features): The zero-indexed geometric features defined in the previous section.
This tool made it incredibly easy to see which specific features carried the most weight for classifying each distinct shape.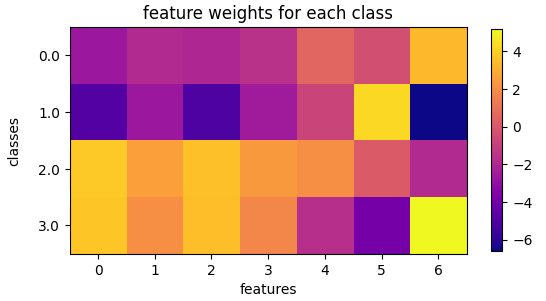
Model Accuracy
The model achieved an amazing classification performance across both training and testing datasets. Using 7 features, the model achieved an accuracy of 94.4% when classifying its training dataset, and an accuracy of 95.3% when classifying a new testing dataset.
Out of 108 test images, the model misclassified only 5 pieces. The 2x4 rectangles and 2x2 circles were identified with near-perfect accuracy because their shape profiles are highly distinct.
The few misclassifications that did occur were between the 2x1 rectangles and the 2x2 squares. Under extreme rotations, edge shadows slightly skewed the bounding box ratios, occasionally causing the model to mistake one shape for the other.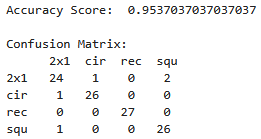
Rows indicate the class of the input and columns indicate the resulting classification the model provides.
Conclusion
This system successfully proved that strategic image processing can resolve complex spatial noise with minimal computing power. Filtering out background artifacts allowed for the extraction of highly accurate, rotation-invariant bounding box metrics. Using just seven engineered geometric features, the model achieved a robust 95.3% testing accuracy on misaligned and rotated items. This minimal feature footprint ensures maximum processing speeds, making it an ideal, production-ready solution for real-time sorting on high-speed industrial conveyor belts.